Understanding HL7 and FHIR: Revolutionizing Healthcare Data Exchange with AWS HealthLake
In today’s fast-paced healthcare environment, the exchange of electronic health data is crucial. With hospitals, clinics, and healthcare providers using a wide range of software applications for everything from patient records to billing, ensuring smooth communication between these systems is a significant challenge. That’s where Health Level-7 (HL7) and Fast Healthcare Interoperability Resources (FHIR) come into play, two standards designed to streamline this process.
What is HL7?
Health Level-7 (HL7) was created by Health Level Seven International, a non-profit organization committed to developing standards for the exchange of electronic healthcare data. HL7 ensures that documentation and data remain consistent, even across different healthcare organizations using various systems.
Most healthcare providers operate a range of software solutions that manage patient information, billing, and administrative tasks. However, these systems often struggle to communicate with one another effectively. HL7 seeks to solve this problem by offering a standardized way to exchange data between these systems. The ultimate goal is to reduce the administrative burden on healthcare staff and providers while improving the overall quality of care.
The Rise of FHIR
As healthcare technology evolved, so did the need for more efficient data sharing. Enter Fast Healthcare Interoperability Resources (FHIR), a next-generation interoperability standard developed by HL7. FHIR is designed specifically for creating and exchanging Electronic Health Records (EHR) between healthcare systems, making it faster and more efficient than previous standards.
HL7 is in a code format whereas FHIR is being represented in XML, JSON etc. FHIR builds on earlier HL7 standards like HL7 version 2.x and HL7 version 3.x, providing a more flexible, web-based approach to sharing data. Its goal is to simplify how healthcare data, including clinical and administrative information, is exchanged across systems, ensuring that providers have access to up-to-date information that can improve patient care.

How HL7 Messages Work
To better understand HL7, it’s important to break down the structure of an HL7 message. These messages are made up of segments, fields, and components. Each segment contains different types of data, with fields separated by a pipe symbol (|), and inner fields separated by a caret (^). This format ensures that data is consistently organized, making it easier to exchange between systems.
The HL7 to FHIR Snap
As healthcare systems increasingly adopt FHIR, the ability to convert data from HL7 to FHIR becomes essential. Enter the HL7 to FHIR Snap, a tool designed to facilitate the conversion of HL7 input documents into FHIR-compliant formats.
Key Features of the HL7 to FHIR Snap:
-
Function: The Snap’s main function is to convert HL7 input documents into FHIR standards, making it easier to exchange data in a format that modern healthcare systems recognize.
-
Options:
-
Label: Allows you to name the Snap for easy identification.
-
Output Format: Choose between JSON or String formats for the converted output.
-
Snap Execution: Provides execution options such as “Validate & Execute,” “Execute Only,” and “Disabled.”
-
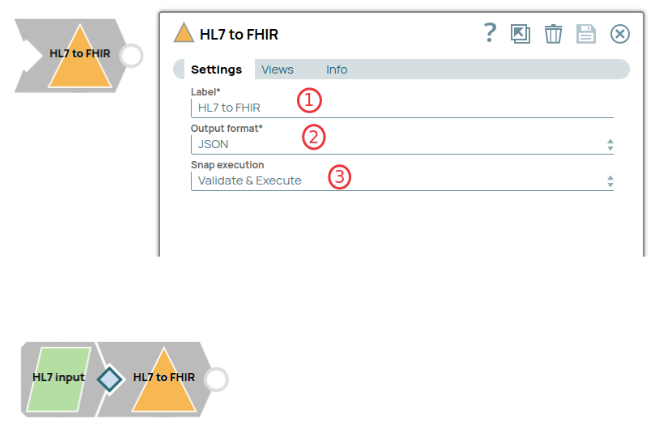
How It Works:
-
The Snap receives HL7 input documents from upstream snaps in the pipeline.
-
It parses these input documents, converting them into FHIR-compliant formats such as JSON or String.
-
The Snap then writes the converted documents to downstream components, ensuring smooth integration with other systems.
AWS HealthLake
As healthcare organizations adopt more advanced data management technologies, AWS HealthLake emerges as a powerful tool in the industry. HealthLake is a HIPAA-eligible service from Amazon Web Services (AWS) that allows healthcare providers to store, transform, and analyze vast amounts of health data in real-time, leveraging the FHIR standard for data interoperability.
HealthLake is built to:
-
Centralize and Normalize Healthcare Data: Import and aggregate health data from disparate systems, including EHRs, to a central repository.
-
Automate Data Transformation: HealthLake converts incoming healthcare data into the FHIR format, making it easier for organizations to unify structured and unstructured data.
-
AI and Machine Learning Insights: By leveraging AWS AI/ML services, healthcare providers can extract valuable insights from the data, helping improve patient outcomes, streamline workflows, and support decision-making.
How FHIR Snap Helps with AWS HealthLake Integration
Integrating legacy healthcare systems with AWS HealthLake often requires converting older HL7 data into the modern FHIR format, and the HL7 to FHIR Snap is instrumental in this transition. Here’s how the FHIR Snap can help in conjunction with AWS HealthLake:
-
Seamless Data Conversion:
-
Healthcare organizations often have large amounts of HL7 data from legacy systems. The FHIR Snap converts this data into FHIR format, which can then be ingested by AWS HealthLake for storage and further analysis.
-
-
Streamlined Integration:
-
By automating the conversion from HL7 to FHIR, the Snap makes it easier to send clean, standardized data to HealthLake. This ensures all data, whether it’s coming from legacy systems or modern applications, is consistent with the FHIR format expected by AWS HealthLake.
-
-
Data Enrichment and AI Insights:
-
Once the data is stored in AWS HealthLake in FHIR format, healthcare providers can leverage AWS's machine learning and natural language processing tools to uncover trends, patterns, and actionable insights from patient data. The FHIR Snap helps ensure that data ingested into HealthLake is structured and ready for advanced analytics.
-
-
Improving Interoperability:
-
FHIR is designed to promote interoperability between healthcare systems. The Snap enables organizations to modernize their data exchange processes, making it easier to share information across platforms, providers, and patients.
-
-
Enhanced Data Security and Compliance:
-
AWS HealthLake ensures data is stored in a HIPAA-eligible environment, and the FHIR Snap facilitates secure and compliant data transfers by handling the sensitive transformation process from legacy HL7 formats to the cloud-ready FHIR standard.
-
Here’s a sample pipeline posting Patient and Encounter information to HealthLake:

Conclusion
As the healthcare industry continues to evolve, the transition from HL7 to FHIR is crucial for improving data interoperability and patient care. The HL7 to FHIR Snap plays an essential role in converting legacy data into the FHIR format, while AWS HealthLake provides a powerful platform to centralize, manage, and analyze healthcare data at scale.
By leveraging the FHIR Snap for data transformation and AWS HealthLake for data storage and analytics, healthcare organizations can unlock the full potential of their data, leading to better care, improved decision-making, and greater operational efficiency.